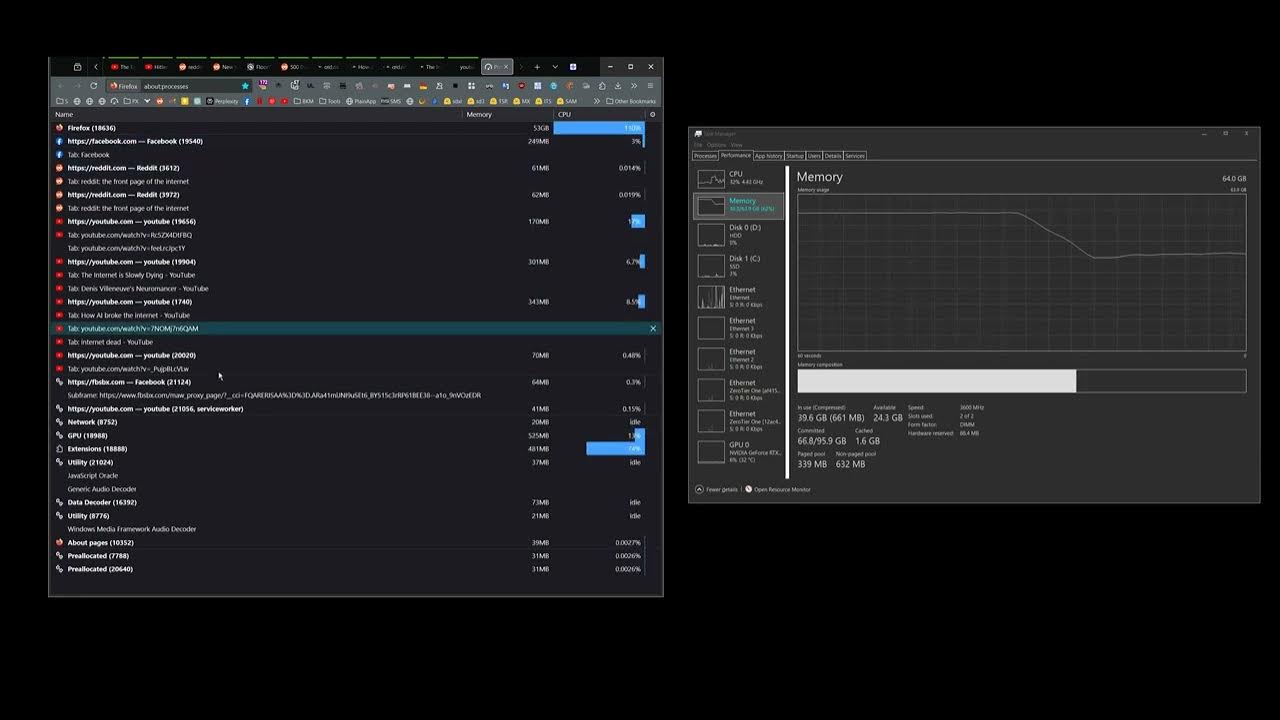
Hi, Once in a while I try to clean up my tabs. First thing I do is use “merge all windows” to put all tabs into one window.
This often causes a memory clog and firefox get stuck in this state for 10-20 minutes
I have recorded one such instance.
I have tried using the “discard all tabs” addon, unfortunately, it is also getting frozen by the memory clog.
Sometimes I will just reboot my PC as that is faster.
Unfortunately, killing firefox this way, does not save the new tab order, so when I start firefox again, it will have 20+ windows open, which I again, merge all pages and then it clogs again !
So far the only solution I have found is just wait the 20 minutes.
Once the “memory clog” is passed, it runs just fine.
I would like better control over tab discard. and maybe some way of limitting bloat. For instance, I would rather keep a lower number of undiscarded youtube that as they seem to be insanely bloated.
In other cases, for most website I would like to never discard the contents.
In my ideal world, I would like the tabs to get frozen and saved to disk permanently, rather than assuming discard tabs can be reloaded. As if the websites were going to exist forever and discarding a tab is like cleaning a cache.
I terminate Firefox and reopen it any time it’s chewing up my RAM, but I usually don’t have more than 500 tabs open at any one time. My tabs persist when Firefox starts again, but tabs don’t fully load until I click on them again. This saves my memory from getting chewed up immediately, and can usually go a week or so before I need to do it again.
You are manually caching web content. Were you aware that (a) your browser does that for you; (b) the internet does that for you ?
I’m as guilty of this as anyone and can tell you from experience that it’s sutpid.
Install Onetab
Rather than try and force Firefox to deal with thousands of tabs, it might be easier to use an add-on like SingleFile to download the tabs as self-contained HTML files. Then once you have the pages downloaded you can search their contents using free tools like Agent Ransack or DocFetcher.
If you still want to keep the data in your browser, then how about using a service like Instapaper that lets you save pages you want to read/reference later?
Why do you have so many tabs open?
If you need quick access to this many pages I suggest organizing bookmarks. As this is what they are meant for. Tabs are meant for active pages you are working with. So anytime you get that many tabs with any browser its gonna run like shit.
That takes too long. Organizing tab is the computer’s job !
I find organizing bookmarks incredibly tedious. I have bookmarks folder with thousands of tabs in and it’s just easier to use google again to re-find the information than to pick them out of bookmarks. Also tabs just keep the title and URL so you can’t even search the text inside. So, organizing a library of tabs is like a much worse version of google without previews. I also use the session manager addon but again, when you open thousands of tabs, it clogs up the memory almost instantly. It’s taking multiple gigabytes of ram, just to display a few kilobytes of text ! I wish the browser would just render the page as a static searchable text and image and then ditch all the javascript garbage.
May I ask why you have to have this level of access to thousands of pages? Even for my job I have maybe 8 active that I use Firefox keywords to jump to.
Nah, FF handles thousands of tabs just fine. I literally have just as many if not more tabs than OP and have never seen this issue. It’s either from the merge they’re doing or something else. It would be better if y’all just worked under the assumption that this does work and something is otherwise wrong with op’s setup.
The issue is parsing all that. There is no way you can keep that many tabs readily accessible like tabs are meant to be. Which is why these addons were born and are not official parts of Firefox. This is one of those just because you can doesn’t mean you should situations. I get they’ve adopted this workflow, but reading through this it sounds more like daily driving than actual work. Which makes this even more bizarre, you can’t read them all, they have to reload when you open them after a while (ie download again) so all points are moot. You aren’t saving the page, you are holding onto a shell that will request the page again when you wake it up. If the server went offline never to be seen again your tab will not hold the information.
With this workflow, it might be better to have a crawler dump everything into folder hierarchies that are content searchable, and then search that like google using specialized software. I dont see any other reason you could even have 1k tabs open efficiently, you aren’t searching through that, might as well google again and follow the purple links.
Reduce to a sane number. Like less than 20.
You’re not likely going to get any real help since you’re insisting on using the browser in an extreme and unconventional way. Your little world is just one browser/OS crash from losing all of those tabs.
What is amazing to me is how some people will come out of the woodwork to tell a person when they think they’re using their browser “wrong”. Just let them be if you have nothing to contribute.
They ARE contributing, in this case the correct answer is “don’t do that”…
Feel free to use your browser how you want, but I will feel free to not help you troubleshoot your problem because it won’t help you in the end.
If someone is trying to achieve a goal through (what they might not know are) impossible means, “letting them be” isn’t going to help them.
Although it might not seem very helpful (and indeed there are better ways of helping) pointing out the flaws in the approach is contributing more than “letting them be”. Doesn’t cost a thing to be civil about it though.
What OP is trying to do isn’t impossible it’s actually very interesting. There are lots of people who use tab workflows instead of bookmarks. And I think everybody would benefit from better in-browser search. Just because bookmarks is how it was done 30 years ago doesn’t mean we can’t try new things.
Unless you bring a solution to the table, taking the position that it isn’t impossible is just cheap contrarianism on your part. Sure we can try new things, but if it doesn’t work and everyone is commenting the approach isn’t helping, then maybe take the hint. Or not, and keep swimming against the stream (in which - seeing OP’s other comments - they seem to be more interested than actually solving the problem)
You dream to small Bookmarks suck and are cumbersome They sucked in 1996 and they still suck today ! Bookmarks have apparently been a crutch to make the browser more usable. Like for instance, instead of discarding a whole tab, keep a text index of the html body and make that searchable. But no, it’s an all of nothing thing, either 2gb of youtube javascript per tab, or we only keep URL and tab title.
Also, you don’t actually need to bring a solution to the table just to say “this thing is not working right” You don’t have to be a mechanic to say “the car is broken” You don’t have to be a doctor to say “this person is sick”
Clearly my message just need to be said over and over until it gets implemented. It is obvious where browsers are going. A total web awareness platform that remembers everything you’ve ever seen. There will be infinite tabs and a local llm will know it all 7 ways from sunday “Firefox, write a song about the 500 first tabs I’ve seen in June 2017, in the style of a broadway musical”
Why would it be impossible to search through tab content if it’s available in memory?
That’s not how it works. Right now the situation is: it doesn’t work. You claim it should be a workable situation. Show how it should work, don’t ask people to prove a negative.
I can save all the tabs easily
Here I show how to save 1775 tabs with one click
Ordering and sorting them, that is an impossible task That’s why i keep them open
1000 tabs? What for?
A small subset of the stuff I’m trying to do.
Is this your goal?

Cause I gotta say, I don’t think abusing your browser is your best bet.
I would settle for just taking over my own computer !
Zotero is a citation manager, with a firefox extension to save an article (but really, a tab) with one click.
It also has fulltext search. You can search snapshots of everything you save.
“But I can’t save all my tabs at once”
(There are some solutions, but nothIng official)
Save as you go. Computers simply don’t have enough ram for 2000 tabs.
Anyway, it also seems to be able to run javascript plugins, and I saw you have some experience with that.
It also has support for folders, so you can organize it a bit better than tabs work for that.
Have you tried increasing the size of your swap memory in windows? Otherwise known as “virtual memory”. Depending on the speed of your drive and available space, you might be able to increase the vertual memory size to get more performance.
But what about using a page archiving service, even a self-hosted one, like Shiori. Shiori has an extension that can allow for single click page archiving right from the browser. The pages are saved as html files or txt files and it will create a readability version of the file which is just the text and images. You could then search the files and their contents using something like VS Code to search the whole directory where the files are stored. There are plenty of other ways to do that search once you have those archives, though. I think even Windows File Search will search the contents of a txt or html file stored on the device.
Shiori also has its own search, which is pretty fast, and searches the contents of the archives as well.
I came to suggest the same. This looks like either swap mem is completely disabled or that the extension OP is using can’t handle the function they’re trying to do.
I am not sure what you’re working on but from your answers I’ve read you seems to need access to a lot of information with a few keystrokes, like searching for a keyword or tag.
In my opinion you are using the wrong tool for that. Ditch the browser and learn about the Zettelkasten way of working. It is really powerful for plenty of applications like science, studies, dev, or even the way I use it, author repository of ideas/concepts/stuff I need when writing a book.
You can do that with several software but I like obsidian for that (and because of all its plugins you could probably find something to automatically copy webpage content)
On the downside side :
- You’ll have to learn Zettelkasten, Obsidian etc
- Obviously do the work of writing (or copy pasting) your vault.
But on the plus size :
- You’ll have all the information you need at your fingertips, searchable with keywords, tags, associations etc.
- Everything is basic text MD files so it will still be readable by any text editor or terminal in the next century.
- You can have images, run code, do some mathlib, jupyter etc inside.
- Text is light, easy to store, backup and retrieve.
- If you do good enough you can have a satisfying visual representation of your new brain, kinda mindmap (which is also possible)
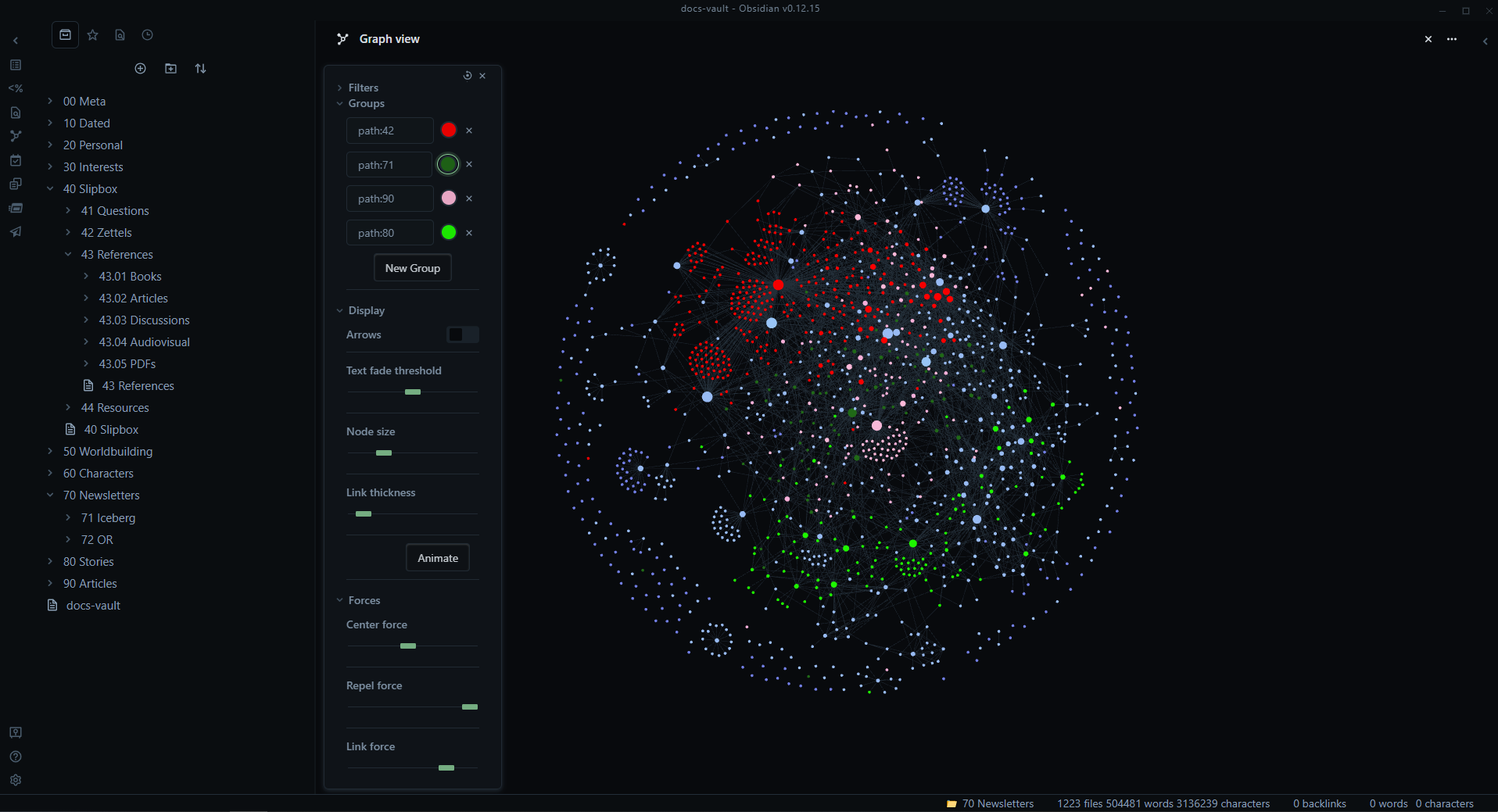
Cool I would love to navigate my data in a manner similar to this. However not obsidian, I am in the process of de-googling and I have severe cloud fatigue. But maybe QOwnNotes
I’m hoping something like Archivebox or squid or some other software can help me, autodump everything in a way that will become accessible to these second party data management software. Hopefully in a manner as transparent as opening a tab.
The solution to write your own application that does what you want because your workflow is not a use case that browsers are designed for. It’s not bad to wish for features but your workflow is never going to be catered for in a browser and it’s both unreasonable and unrealistic to expect otherwise - hence you need to do it yourself.
If you can’t or don’t know how to do that yourself, I suggest you listen to the advice everyone else is giving you. Organisation does require ongoing work and given your comments it will likely require a lot of upfront effort to change your browser hygiene habits but once you are more organised it becomes a lot easier and a lot less work to stay on top of things.
It’s none of my business but I wonder why you feel it’s so important to open 500+ tabs just to buy something small online. Doing research and being informed is good but it seems disproportionate and perhaps talking to a professional might help you with that.
browser hygiene habits
You used that term, and frankly I recoil a bit a this term because of the implication that it’s not a deficiency of the software but that it’s the users who are wrong.
Still, I typed in the phrase into chatgpt
And I see “reading lists” as an alternative to bookmarks (that I find to be, straight up unusable)
So I found this reading list addon give a try.
https://addons.mozilla.org/en-GB/firefox/addon/reading_list/
I have a very specific use for a “reading list”, which I take to be something like a FIFO stack of links. And that would be going through youtube videos.
Putting this in case someone else is reading this thread looking for answers.
However, it’s a side bar thing, and you have to add links one at a time, can’t select multiple tabs and add them
As for opening 500+ tabs to buy a thing.
You do know that sellers now use algorithmic pricing and often there will be hundreds of sellers for the same thing.
Plus the price will be obfuscated with various artifices that all have to be overcome to find the best seller with the best price.
Defeating all of that means openning a shit-ton of tabs.
Here’s an example of the process I’ve designed for aliexpress
https://github.com/igorlogius/gather-from-tabs/discussions/8
You used that term, and frankly I recoil a bit a this term because of the implication that it’s not a deficiency of the software but that it’s the users who are wrong.
I wouldn’t say FF is deficient in this case - not being designed for your exact use case doesn’t mean there’s anything wrong with it.
As for opening 500+ tabs to buy a thing.
You do know that sellers now use algorithmic pricing and often there will be hundreds of sellers for the same thing.
Plus the price will be obfuscated with various artifices that all have to be overcome to find the best seller with the best price.
Defeating all of that means openning a shit-ton of tabs.
I usually only buy things if I agree with the price it’s being sold at. If I don’t I will look elsewhere but ultimately I value my time more than money. Extra money can be earned, time cannot 🤷♂️ If you have to drive 100 miles to a fuel station to save 2 cent per gallon, are you actually saving money?
Here’s an example of the process I’ve designed for aliexpress
https://github.com/igorlogius/gather-from-tabs/discussions/8
So it’s a script generating all the tabs?
No, I have to setup all the tabs in just the right way. Then for each tabs it gets the price and shipping information I paste that into excel Combine the total together and sort with ascending price Then I repeat that for every quantity value for 1,2,3,4,5,7,10,15,20,25,50,75,100 Then I find the minimum quantity to get the best price.
This is because if you go to the website and just ask “order by price” it either hides most results, or straight up lies and still place them out of order. It also lies about the shipping cost. But it can’t lie on the last page before clicking buy.
I expect the internet to continue becoming more deceptive and manipulative in this manner, my method is almost not good enough. If my tools don’t continue to evolve it will simply become impossible to find the best price for anything. It will all become an endless maze where they measure how much mental stamina you’re willing to waste to save another dollar. At that point the price of things will become whatever the maximum you individually will bear.
Not sure what your coding level is but you could interact with and scrape the sites with python. I’m sure other languages have similar frameworks.
Even if you aren’t very familiar and don’t know any pythons, it’s a good one to learn and though it could take a while to learn enough to do what you want, you would be more motivated to figure things out and it would save you a lot of time (and money) in the long term.
https://realpython.com/modern-web-automation-with-python-and-selenium/.
https://www.projectpro.io/article/python-libraries-for-web-scraping/625
A tab suspender extension might help some, but there’s only so much you can do to minimize the impact of thousand(s) of tabs. Cleaning out old tabs more frequently is probably a better habit.
I tried a tab suspender, but it would replace tabs with a moz:// address that would end up breaking all my tabs when I copy & pasted them from a text file. Also tab suspender doesn’t work once firefox gets into that state. I think the internal scheduler is trying to load tabs and discarding them as fast as possible. What I need is a big “stop button” that stop it all from at least trying to load new tabs.
I think what’s happenning is when I merge all windows, many gets get woken up and, like the youtube tabs they seem to gobble up 2 to 4 gb of ram while initializing to that freezes everything.
It’s making it really hard to get to 10k 20k tabs when it really falls apart like that with not even 2k tabs.
This makes the browser experience really bogged down where most of the time is spent finishing and closing tabs instead of just getting on with the actual task.
I would really like to spend less time fiddling with my browser and it “just working”.
20k tabs? I struggle to see how someone could go through that many tabs, even over a long period of time. Your workflow is something the browser was never made to handle.
Try some popular non-Mozilla tab suspend extensions. I doubt that they all operate the same way.
The thing is that, it does work fine as long as I don’t disturb too many tabs. It’s the action of agglomerating all tabs to a single window that wakes up a bunch of tabs unnecessarily Surely there’s a shortcut or something to “stop all tabs” immediately. I would even take a “discard all tabs” to flush the tab memory. It seems to be what happens after a while, but it takes more than 5 minutes to happen on its own.
geez, just press Ctrl+W when you’re done with a tab, or if the tab is older than a couple hours
I don’t understand why some are so attached to tabs. Search your history if you need it again.
I tried closing tabs, I have to finish reading them, make sure I got everything and that whatever reason I had for opening that tab was done. The result is that I spend all most all my time trying to close and sort and order tabs instead of doing what I was trying to do in the first place. And then the browser freezes for 10 minutes.
Something is very wrong that 64GB is nowhere near enough to handle a few megabytes of text. And searching text inside of all tabs is an unthinkably difficult operation ?
Where did the web go wrong !?
It’s not the web. It seems to me you might have an attention deficit issue. Try improving your workflow.
My computer should bend to my will, not the other way around.
Say these problems are fixed for now. How many tabs is enough? How do you see this tab hoarding progression being sustainable at all?
I would put the full text, image and video of every tab I have ever opened into the context memory of an open source LLM if I could. I would only consciously delete stuff that needs to stop existing immediately, like doxxing data or illegal data or malicious code.
This is like asking, how many email should you keep.
Well at work we auto delete all emails after 60 days.
But my personal email has every email going back to 2006, the last storage failure before backup, and it’s all quickly searchable.
The other limit would be storage space, but my cluster has still 180 terabyte empty space, I don’t see that getting filled up from plain browser data any time soon.
Of course, I would like better automated data catalogging tools. I would like to ask my local open source LLM to “pull up all tabs regarding 7 megahertz maser project” and it should should open a browser window that contains every tab I have ever come accross on that topic. Including now-dead websites. It should all be sorted by date, it should know to put the more basic tabs to the left and the cutting edge stuff on the right. All this without me tagging a single thing, without wasting a minute of my time doing sorting busywork.
It is the job of the computer to organize my data, in an offline, private, reliable, open source-based, enshittification-proof manner with infinite memory and perfect recall. So that I can get on with doing the stuff that I want to do and not fiddle with browser settings.
Mozilla foundation has revenues in the 500 million range and a 7 million a year CEO, I expect nothing less.
I applaud their initiative with llamafile, however I hope that was just an appetizer.
yeah mate - you need a knowledge management software, not a browser.
tabs were always ephemeral and that’s unlikely to change because they’re much more than text and images.
that’s simply an unreasonable expectation for a browser.
I’m honestly surprised Firefox even handles more than a few hundred open tabs.
That’s fair, maybe you’re using the wrong tool though, something like an internet archive sounds more like what you need.
Take every tab you open and save a PDF, all the text, and all the images, then put a timestamp on them before deleting the tab. That’s not the point of a browser though, that’s an entirely different product.
You’re welcome to build it though, or ask Microsoft if they can make Recall work for tabs.
I was going to also say that OP might be wanting something like Recall (which might be one of the few instances where it constantly saving shit would be perfect). But they would need like the most extreme version that isn’t just saving searchable screenshots.
I also think that one major issue for OP is more about how the actual sites are coded these days. As even if a single tab is being used, the shit can just decide to force it to update the contents at any time (like how just having Gmail open you will see new messages just show up even without refreshing your browser).
It seems like the perfect situation for OP would be if the web still worked like it did pre-web 2.0, but with using the current version of FF. Outside of that, it really seems like they need to just start having sites be auto-completely downloaded for full offline use.
I am still shocked that the main issues being had seems to be that it taking 10s of mins to allow FF to process that much stuff is the frustration. Which does seem to mean FF is holding up pretty well given the situation. Their complaint about tab isolation being too much overhead seems odd though. As it would seem that going back to not having that would mean a much higher chance of just everything just being yeet-ed out of nowhere.
I am not sure how their headspace of using virtual machines approach would be much better as shit would still have the issues of sites still self-updating and loading up in the first place. Though given they seem to have dramatically more coding experience, I am much more ignorant of this shit.
Then invent the technology that makes what you want to do reasonable, otherwise don’t blame a drill for being incapable of hammering nails fast enough for you.